publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- ICCV
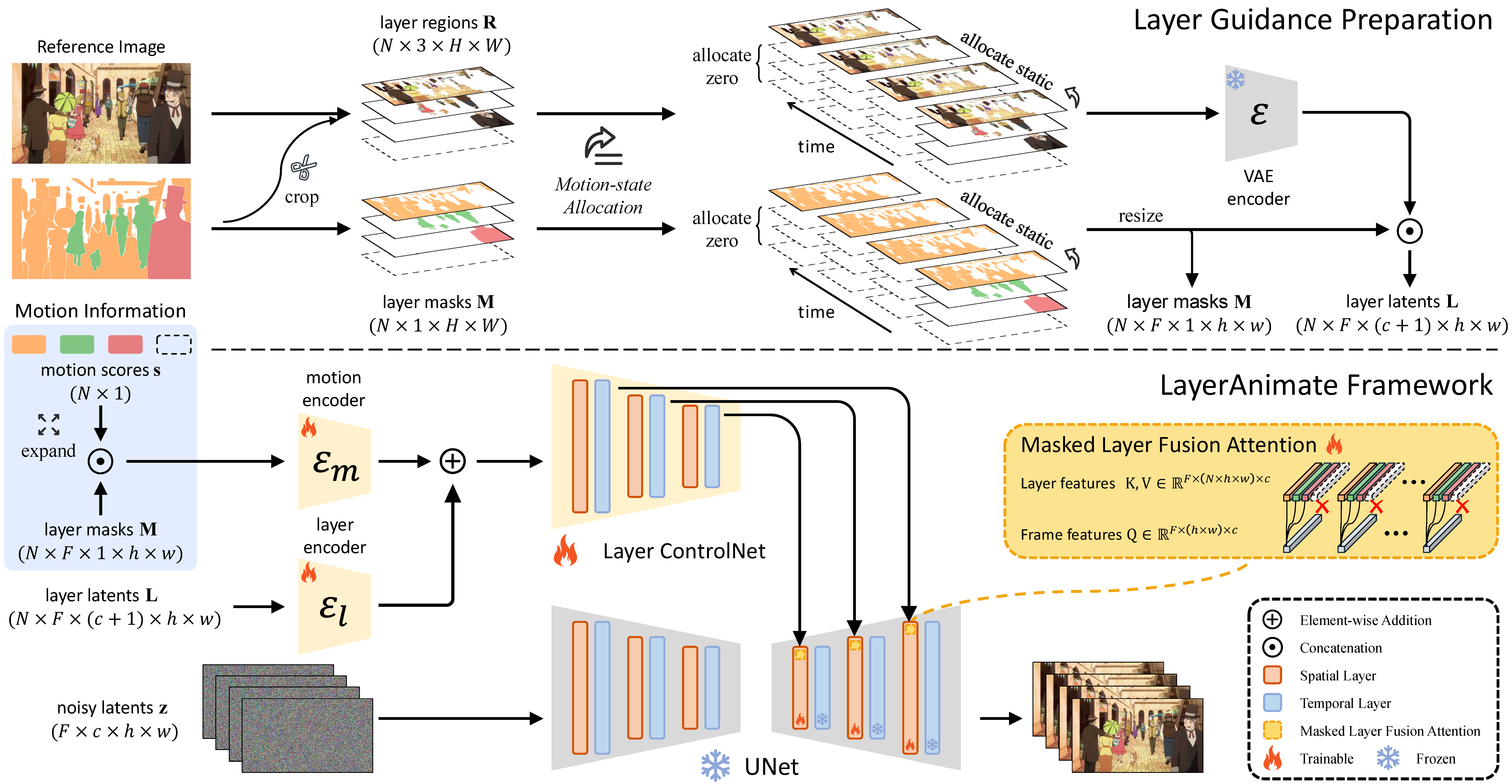 LayerAnimate: Layer-level Control for AnimationYuxue Yang, Lue Fan, Zuzeng Lin, Feng Wang, and Zhaoxiang Zhang†In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , Oct 2025
LayerAnimate: Layer-level Control for AnimationYuxue Yang, Lue Fan, Zuzeng Lin, Feng Wang, and Zhaoxiang Zhang†In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , Oct 2025Traditional animation production decomposes visual elements into discrete layers to enable independent processing for sketching, refining, coloring, and in-betweening. Existing anime generation video methods typically treat animation as a distinct data domain different from real-world videos, lacking fine-grained control at the layer level. To bridge this gap, we introduce LayerAnimate, a novel video diffusion framework with layer-aware architecture that empowers the manipulation of layers through layer-level controls. The development of a layer-aware framework faces a significant data scarcity challenge due to the commercial sensitivity of professional animation assets. To address the limitation, we propose a data curation pipeline featuring Automated Element Segmentation and Motion-based Hierarchical Merging. Through quantitative and qualitative comparisons, and user study, we demonstrate that LayerAnimate outperforms current methods in terms of animation quality, control precision, and usability, making it an effective tool for both professional animators and amateur enthusiasts. This framework opens up new possibilities for layer-level animation applications and creative flexibility. Our code is available at https://layeranimate.github.io.

2024
-
 Trim 3D Gaussian Splatting for Accurate Geometry RepresentationLue Fan*, Yuxue Yang*, Minxing Li, Hongsheng Li†, and Zhaoxiang Zhang†arXiv preprint arXiv:2406.07499, Oct 2024
Trim 3D Gaussian Splatting for Accurate Geometry RepresentationLue Fan*, Yuxue Yang*, Minxing Li, Hongsheng Li†, and Zhaoxiang Zhang†arXiv preprint arXiv:2406.07499, Oct 2024In this paper, we introduce Trim 3D Gaussian Splatting (TrimGS) to reconstruct accurate 3D geometry from images. Previous arts for geometry reconstruction from 3D Gaussians mainly focus on exploring strong geometry regularization. Instead, from a fresh perspective, we propose to obtain accurate 3D geometry of a scene by Gaussian trimming, which selectively removes the inaccurate geometry while preserving accurate structures. To achieve this, we analyze the contributions of individual 3D Gaussians and propose a contribution-based trimming strategy to remove the redundant or inaccurate Gaussians. Furthermore, our experimental and theoretical analyses reveal that a relatively small Gaussian scale is a non-negligible factor in representing and optimizing the intricate details. Therefore the proposed TrimGS maintains relatively small Gaussian scales. In addition, TrimGS is also compatible with the effective geometry regularization strategies in previous arts. When combined with the original 3DGS and the state-of-the-art 2DGS, TrimGS consistently yields more accurate geometry and higher perceptual quality.
- ICLR
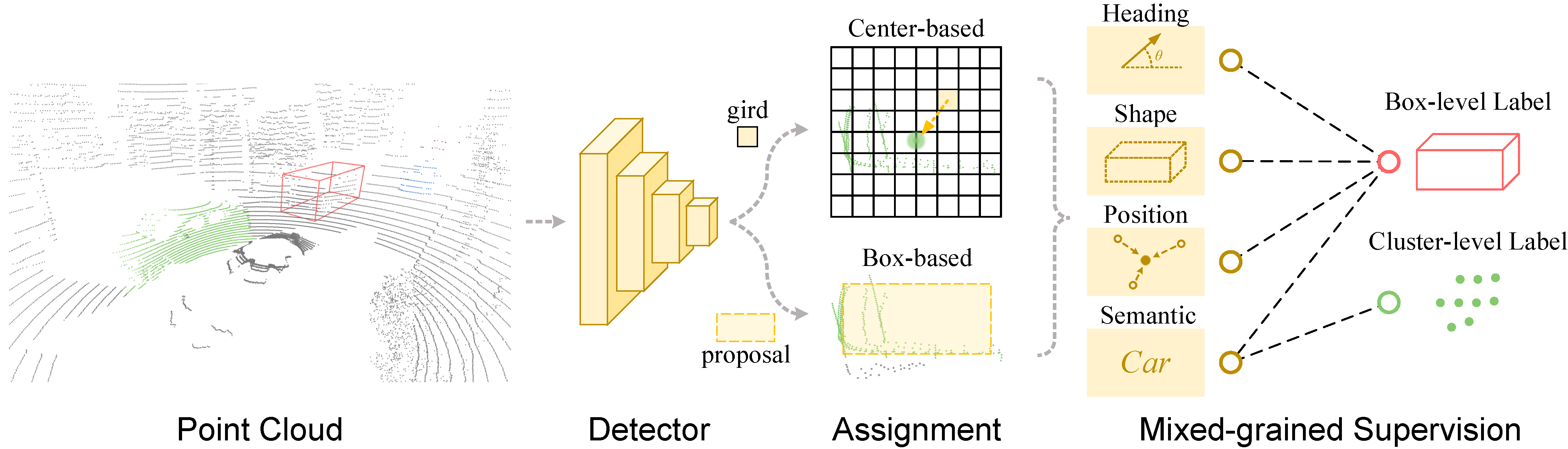 MixSup: Mixed-grained Supervision for Label-efficient LiDAR-based 3D Object DetectionYuxue Yang, Lue Fan†, and Zhaoxiang Zhang†In The Twelfth International Conference on Learning Representations (ICLR) , Oct 2024
MixSup: Mixed-grained Supervision for Label-efficient LiDAR-based 3D Object DetectionYuxue Yang, Lue Fan†, and Zhaoxiang Zhang†In The Twelfth International Conference on Learning Representations (ICLR) , Oct 2024Label-efficient LiDAR-based 3D object detection is currently dominated by weakly/semi-supervised methods. Instead of exclusively following one of them, we propose MixSup, a more practical paradigm simultaneously utilizing massive cheap coarse labels and a limited number of accurate labels for Mixed-grained Supervision. We start by observing that point clouds are usually textureless, making it hard to learn semantics. However, point clouds are geometrically rich and scale-invariant to the distances from sensors, making it relatively easy to learn the geometry of objects, such as poses and shapes. Thus, MixSup leverages massive coarse cluster-level labels to learn semantics and a few expensive box-level labels to learn accurate poses and shapes. We redesign the label assignment in mainstream detectors, which allows them seamlessly integrated into MixSup, enabling practicality and universality. We validate its effectiveness in nuScenes, Waymo Open Dataset, and KITTI, employing various detectors. MixSup achieves up to 97.31% of fully supervised performance, using cheap cluster annotations and only 10% box annotations. Furthermore, we propose PointSAM based on the Segment Anything Model for automated coarse labeling, further reducing the annotation burden. The code is available at https://github.com/BraveGroup/PointSAM-for-MixSup.


2023
- ICCV
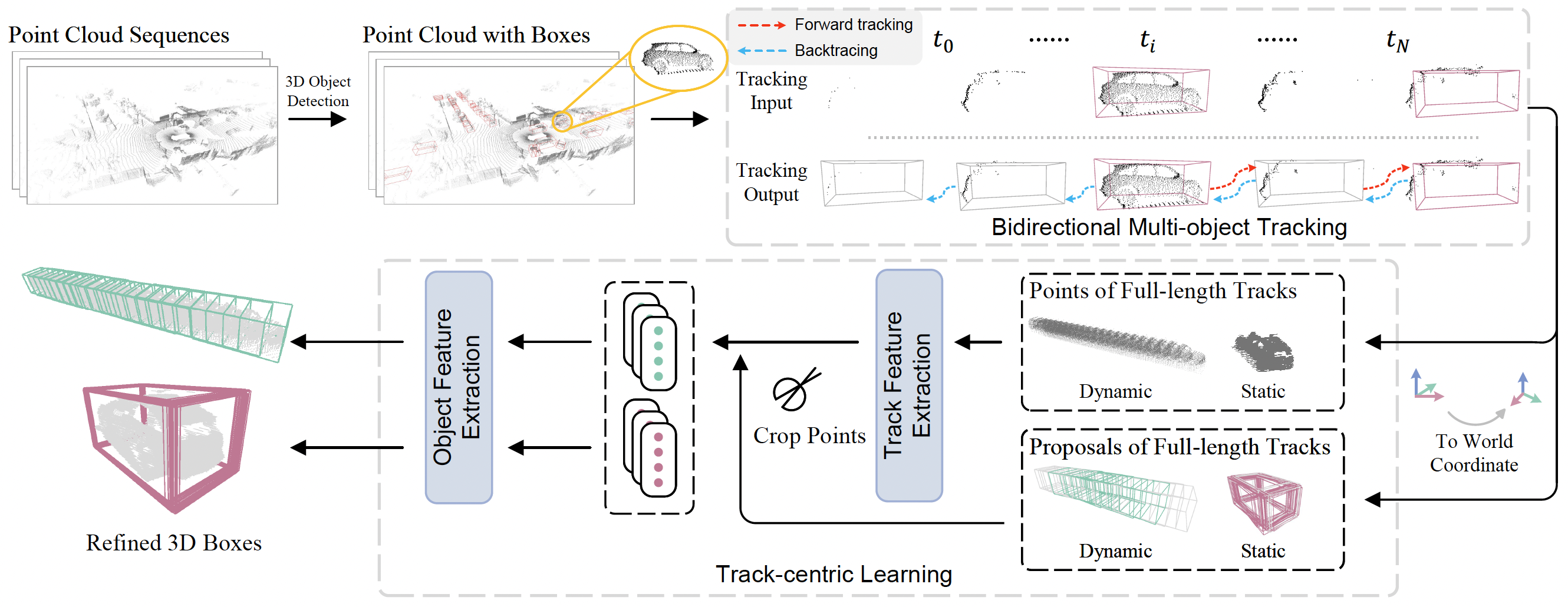 Once Detected, Never Lost: Surpassing Human Performance in Offline LiDAR based 3D Object DetectionLue Fan, Yuxue Yang, Yiming Mao, Feng Wang, Yuntao Chen, Naiyan Wang, and Zhaoxiang ZhangIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , Oct 2023
Once Detected, Never Lost: Surpassing Human Performance in Offline LiDAR based 3D Object DetectionLue Fan, Yuxue Yang, Yiming Mao, Feng Wang, Yuntao Chen, Naiyan Wang, and Zhaoxiang ZhangIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , Oct 2023This paper aims for high-performance offline LiDAR-based 3D object detection. We first observe that experienced human annotators annotate objects from a track-centric perspective. They first label objects in a track with clear shapes, and then leverage the temporal coherence to infer the annotations of obscure objects. Drawing inspiration from this, we propose a high-performance offline detector in a track-centric perspective instead of the conventional object-centric perspective. Our method features a bidirectional tracking module and a track-centric learning module. Such a design allows our detector to infer and refine a complete track once the object is detected at a certain moment. We refer to this characteristic as "onCe detecTed, neveR Lost" and name the proposed system CTRL. Extensive experiments demonstrate the remarkable performance of our method, surpassing the human-level annotating accuracy and outperforming the previous state-of-the-art methods in the highly competitive Waymo Open Dataset leaderboard without model ensemble. The code is available at https://github.com/tusen-ai/SST.
- TPAMI
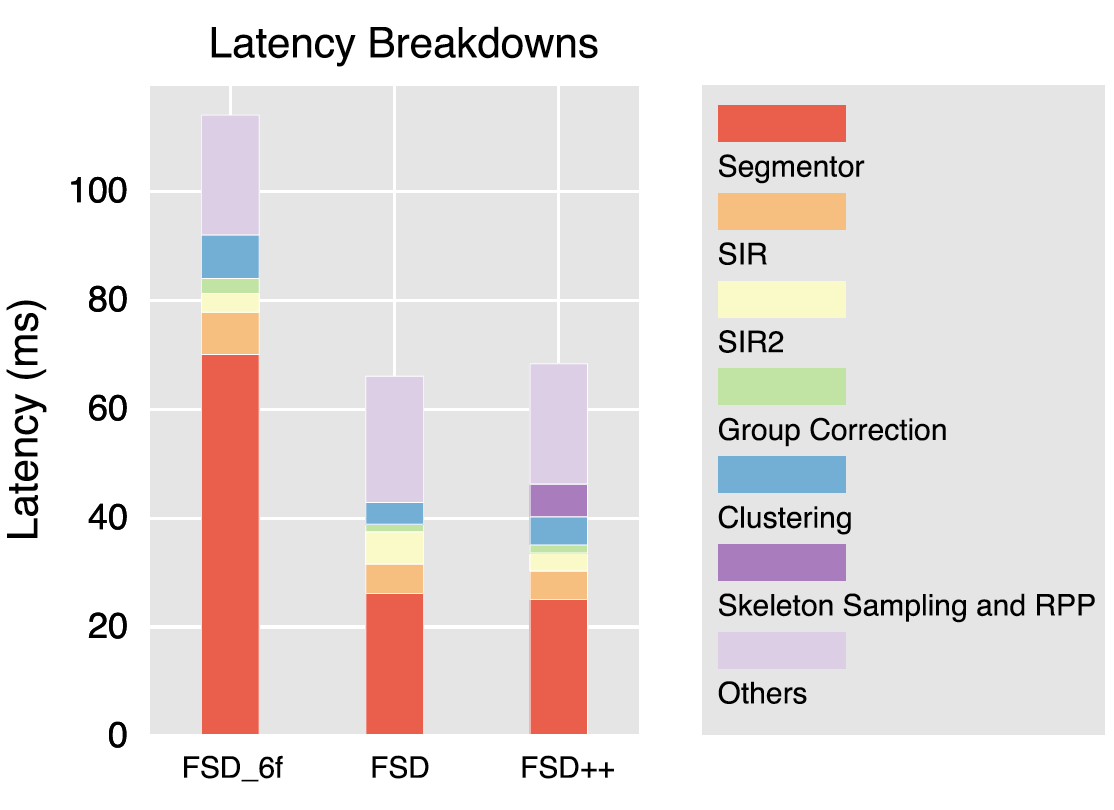 Super Sparse 3D Object DetectionLue Fan, Yuxue Yang, Feng Wang, Naiyan Wang, and Zhaoxiang ZhangIEEE Transactions on Pattern Analysis and Machine Intelligence, Oct 2023
Super Sparse 3D Object DetectionLue Fan, Yuxue Yang, Feng Wang, Naiyan Wang, and Zhaoxiang ZhangIEEE Transactions on Pattern Analysis and Machine Intelligence, Oct 2023As the perception range of LiDAR expands, LiDAR-based 3D object detection contributes ever-increasingly to the long-range perception in autonomous driving. Mainstream 3D object detectors often build dense feature maps, where the cost is quadratic to the perception range, making them hardly scale up to the long-range settings. To enable efficient long-range detection, we first propose a fully sparse object detector termed FSD. FSD is built upon the general sparse voxel encoder and a novel sparse instance recognition (SIR) module. SIR groups the points into instances and applies highly-efficient instance-wise feature extraction. The instance-wise grouping sidesteps the issue of the center feature missing, which hinders the design of the fully sparse architecture. To further enjoy the benefit of fully sparse characteristic, we leverage temporal information to remove data redundancy and propose a super sparse detector named FSD++. FSD++ first generates residual points, which indicate the point changes between consecutive frames. The residual points, along with a few previous foreground points, form the super sparse input data, greatly reducing data redundancy and computational overhead. We comprehensively analyze our method on the large-scale Waymo Open Dataset, and state-of-the-art performance is reported. To showcase the superiority of our method in long-range detection, we also conduct experiments on Argoverse 2 Dataset, where the perception range ( 200 m) is much larger than Waymo Open Dataset ( 75 m).
- CVPR
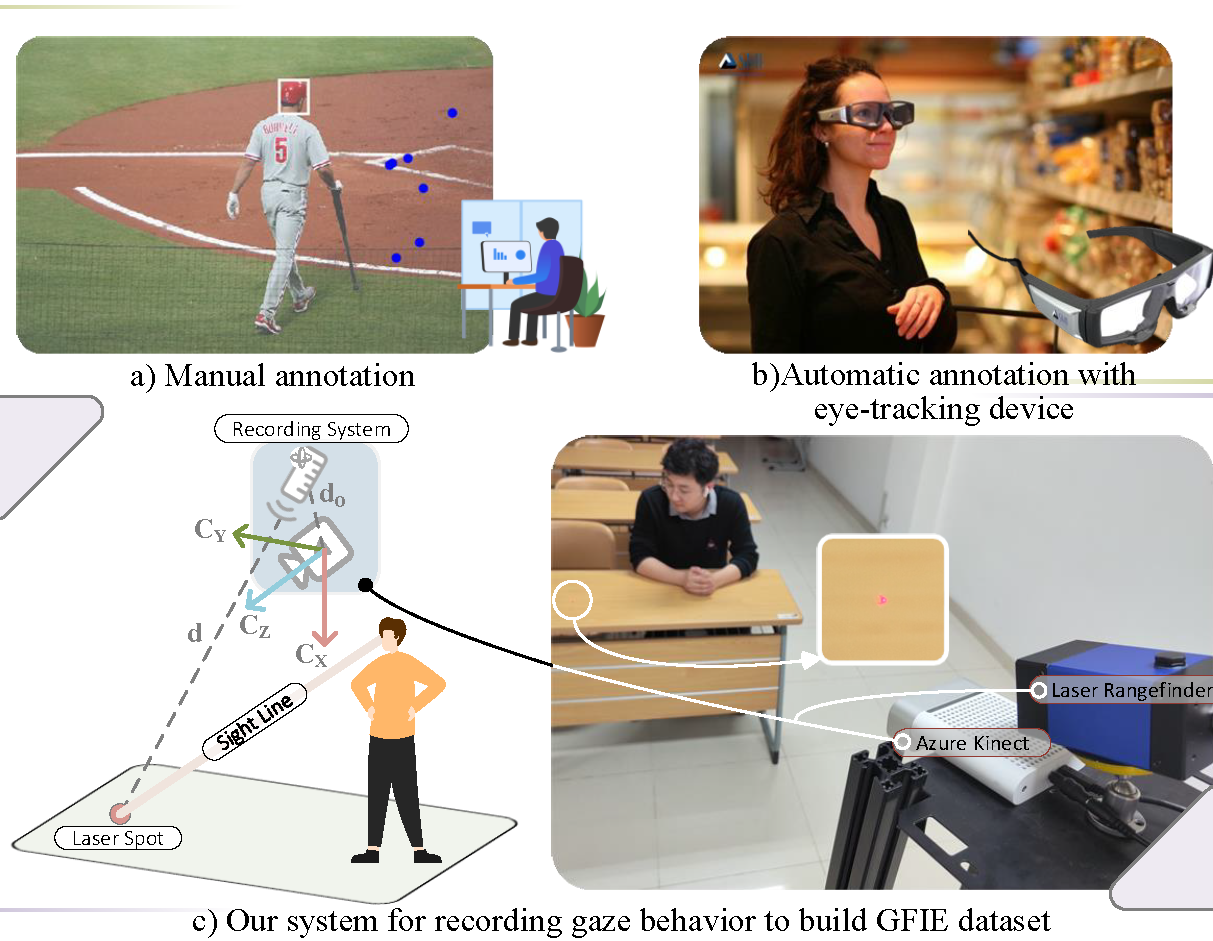 GFIE: A Dataset and Baseline for Gaze-Following From 2D to 3D in Indoor EnvironmentsZhengxi Hu, Yuxue Yang, Xiaolin Zhai, Dingye Yang, Bohan Zhou, and Jingtai LiuIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2023
GFIE: A Dataset and Baseline for Gaze-Following From 2D to 3D in Indoor EnvironmentsZhengxi Hu, Yuxue Yang, Xiaolin Zhai, Dingye Yang, Bohan Zhou, and Jingtai LiuIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2023Gaze-following is a kind of research that requires locating where the person in the scene is looking automatically under the topic of gaze estimation. It is an important clue for understanding human intention, such as identifying objects or regions of interest to humans. However, a survey of datasets used for gaze-following tasks reveals defects in the way they collect gaze point labels. Manual labeling may introduce subjective bias and is labor-intensive, while automatic labeling with an eye-tracking device would alter the person’s appearance. In this work, we introduce GFIE, a novel dataset recorded by a gaze data collection system we developed. The system is constructed with two devices, an Azure Kinect and a laser rangefinder, which generate the laser spot to steer the subject’s attention as they perform in front of the camera. And an algorithm is developed to locate laser spots in images for annotating 2D/3D gaze targets and removing ground truth introduced by the spots. The whole procedure of collecting gaze behavior allows us to obtain unbiased labels in unconstrained environments semi-automatically. We also propose a baseline method with stereo field-of-view (FoV) perception for establishing a 2D/3D gaze-following benchmark on the GFIE dataset. Project page: https://sites.google.com/view/gfie.


